
I am currently an associate professor in John Hopcroft Center of Shanghai Jiao Tong University.
My research interests include AR/VR, avatars/characters, 3D animations, HCI, and computer graphics. Previously, I was an Associate Research Scientist in AR/VR at Disney Research Los Angeles. I received the B.Sc. degree in communication and information engineering from Purdue/UESTC in 2010 and the Ph.D. degree in computer graphics from the University College London (UCL) in 2015. I has served as Associate Editor of the International Journal of Human Computer Studies, and a regular member of IEEE virtual reality program committees.
I am looking for self-motivated PhD, master and undergraduate students to join my research group. My E-mail address is whitneypanye@sjtu.edu.cn. Please contact me if you are interested.
📖 Educations
- 2011.09 - 2015.02, University College London, PhD.
- 2010.09 - 2011.09, University College London, Master.
- 2006.09 - 2010.07, University of Electronic Science and technology, Bachelor.
💻 Work Experience
- 2020.11 - Present, Shanghai Jiao Tong University, Associate Professor.
- 2017.09 - 2020.10, Disney Research Los Angeles, Associate Research Scientist.
- 2015.02 - 2017.09, University College London, Postdoc.
🔥 News
- 2025.12: 🎉🎉 2 papers accepted to TVCG 2026
- 2025.11: 🎉🎉 1 paper accepted to AAAI 2026
- 2025.09: 🎉🎉 1 paper accepted to ICCV 2025 (Best Paper Candidate)
- 2025.07: 🎉🎉 2 paper accepted to ACMMM 2025
📝 Publications
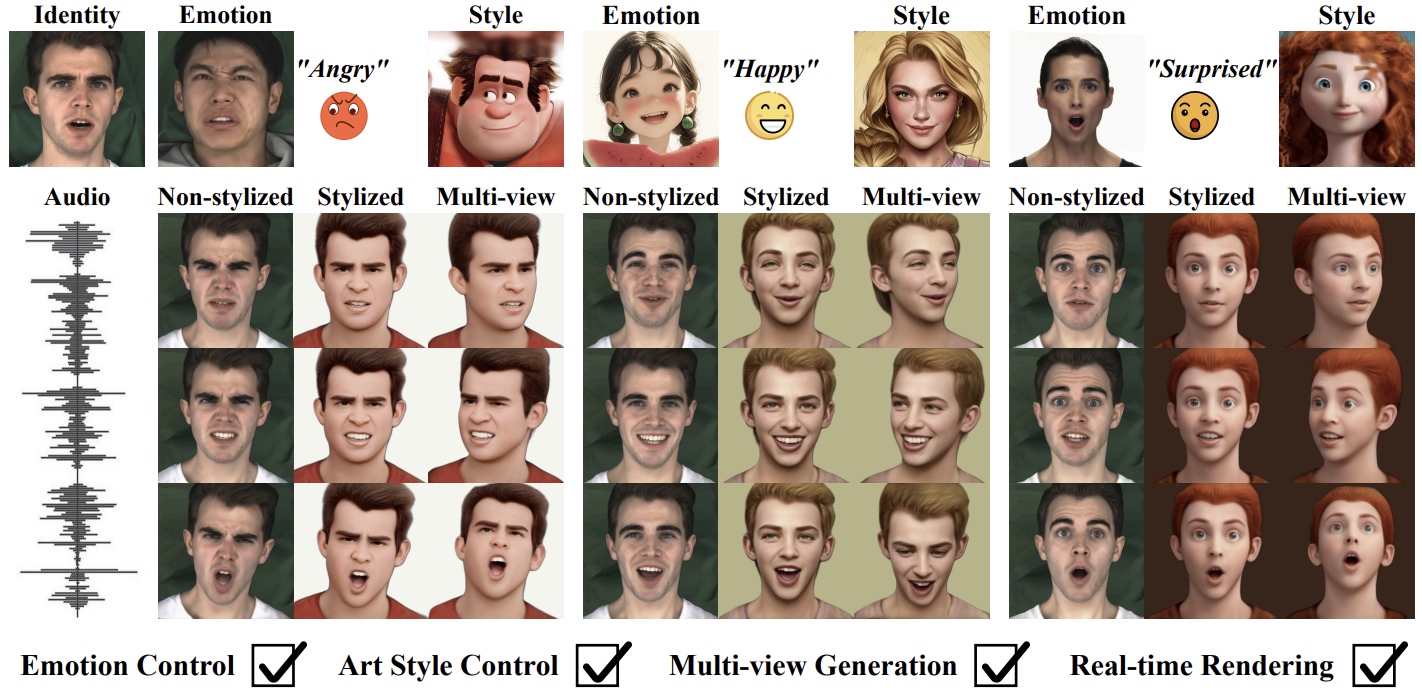
ESGaussianFace: Emotional and Stylized Audio-Driven Facial Animation via 3D Gaussian Splatting
Chuhang Ma, Shuai Tan, Ye Pan, Jiaolong Yang, Xin Tong
- Most current audio-driven facial animation research primarily focuses on generating videos with neutral emotions. While some studies have addressed the generation of facial videos driven by emotional audio, efficiently generating high-quality talking head videos that integrate both emotional expressions and style features remains a significant challenge. In this paper, we propose ESGaussianFace, an innovative framework for emotional and stylized audio-driven facial animation. Our approach leverages 3D Gaussian Splatting to reconstruct 3D scenes and render videos, ensuring efficient generation of 3D consistent results. We propose an emotion-audio-guided spatial attention method that effectively integrates emotion features with audio content features. Through emotion-guided attention, the model is able to reconstruct facial details across different emotional states more accurately. To achieve emotional and stylized deformations of the 3D Gaussian points through emotion and style features, we introduce two 3D Gaussian deformation predictors. Futhermore, we propose a multi-stage training strategy, enabling the step-by-step learning of the character’s lip movements, emotional variations, and style features. Our generated results exhibit high efficiency, high quality, and 3D consistency. Extensive experimental results demonstrate that our method outperforms existing state-of-the-art techniques in terms of lip movement accuracy, expression variation, and style feature expressiveness.
DiffPortraitVideo: Diffusion-based Expression-Consistent Zero-Shot Portrait Video Translation
Shaoxu Li, Chuhang Ma, Ye Pan
- Zero-shot text-to-video diffusion models are crafted to expand pre-trained image diffusion models to the video domain without additional training. In recent times, prevailing techniques commonly rely on existing shapes as constraints and introduce inter-frame attention to ensure texture consistency. However, such shape constraints tend to restrict the stylized geometric deformation of videos and inadvertently neglect the original texture characteristics. Furthermore, existing methods suffer from flickering and inconsistent facial expressions. In this paper, we present DiffPortraitVideo. The framework employs a diffusion model-based feature and attention injection mechanism to generate key frames, with cross-frame constraints to enforce coherence and adaptive feature fusion to ensure expression consistency. Our approach achieves high spatio-temporal and expression consistency while retaining the textual and original image properties. Extensive and comprehensive experiments are conducted to validate the efficacy of our proposed framework in generating personalized, high-quality, and coherent videos. This not only showcases the superiority of our method over existing approaches but also paves the way for further research and development in the field of text-to-video generation with enhanced personalization and quality.

GOES: 3D Gaussian-based One-shot Head Animation with Any Emotion and Any Style
Chuhang Ma, Shuai Tan, Junjie Wei, Ye Pan
- Recent advancements in one-shot head avatar generation and animation have garnered significant attention. However, previous works primarily focus on maintaining consistency in expression and pose between the output and driving images, with limited exploration of two crucial factors: emotion and style. In this paper, we introduce GOES, an 3D Gaussian based One-shot head animation framework for any Emotion and any Style. To achieve low rendering consumption and high reenactment speeds, we incorporate 3D Gaussian techniques into our method. Compared to controlling facial emotions with a single label, using an image as the emotion source enables more precise and fine-grained emotional expression modeling. To accurately extract emotion features from any given image, we design an efficient emotion encoder. Based on this module, we employ a deformation predictor to achieve the emotion-driven deformation of facial 3D points. Regarding stylization, directly using style features to control the deformation of 3D Gaussian parameters results in global color changes. However, facial stylization requires region-specific color transformations. To address this, we propose a Global-to-Point mapping network, which maps the global style feature to each 3D Gaussian points. This module enables precise local style adaptation across different regions of the head avatar. Experimental results demonstrate that our approach outperforms existing methods in terms of facial reconstruction quality and expression accuracy, while also supporting customization of arbitrary emotions and styles.
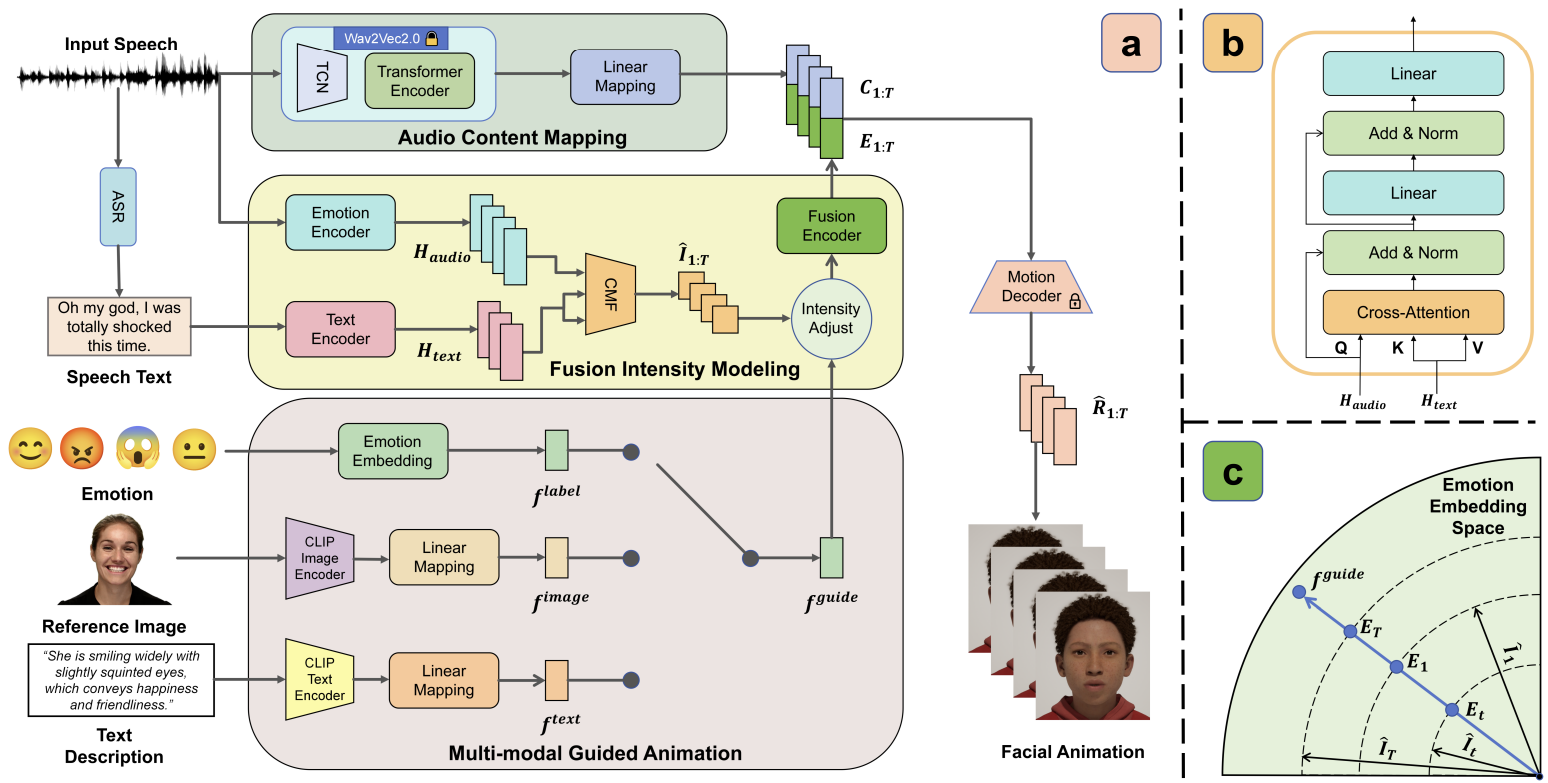
Medtalk: Multimodal controlled 3d facial animation with dynamic emotions by disentangled embedding
Chang Liu, Ye Pan, Chenyang Ding, Susanto Rahardja, Xiaokang Yang
- Audio-driven emotional 3D facial animation aims to generate synchronized lip movements and vivid facial expressions. However, most existing approaches focus on static and predefined emotion labels, limiting their diversity and naturalness. To address these challenges, we propose MEDTalk, a novel framework for fine-grained and dynamic emotional talking head generation. Our approach first disentangles content and emotion embedding spaces from motion sequences using a carefully designed cross-reconstruction process, enabling independent control over lip movements and facial expressions. Beyond conventional audio-driven lip synchronization, we integrate audio and speech text, predicting frame-wise intensity variations and dynamically adjusting static emotion features to generate realistic emotional expressions. Furthermore, to enhance control and personalization, we incorporate multimodal inputs-including text descriptions and reference expression images-to guide the generation of user-specified facial expressions. With MetaHuman as the priority, our generated results can be conveniently integrated into the industrial production pipeline. The code is available at: https://github.com/SJTU-Lucy/MEDTalk.
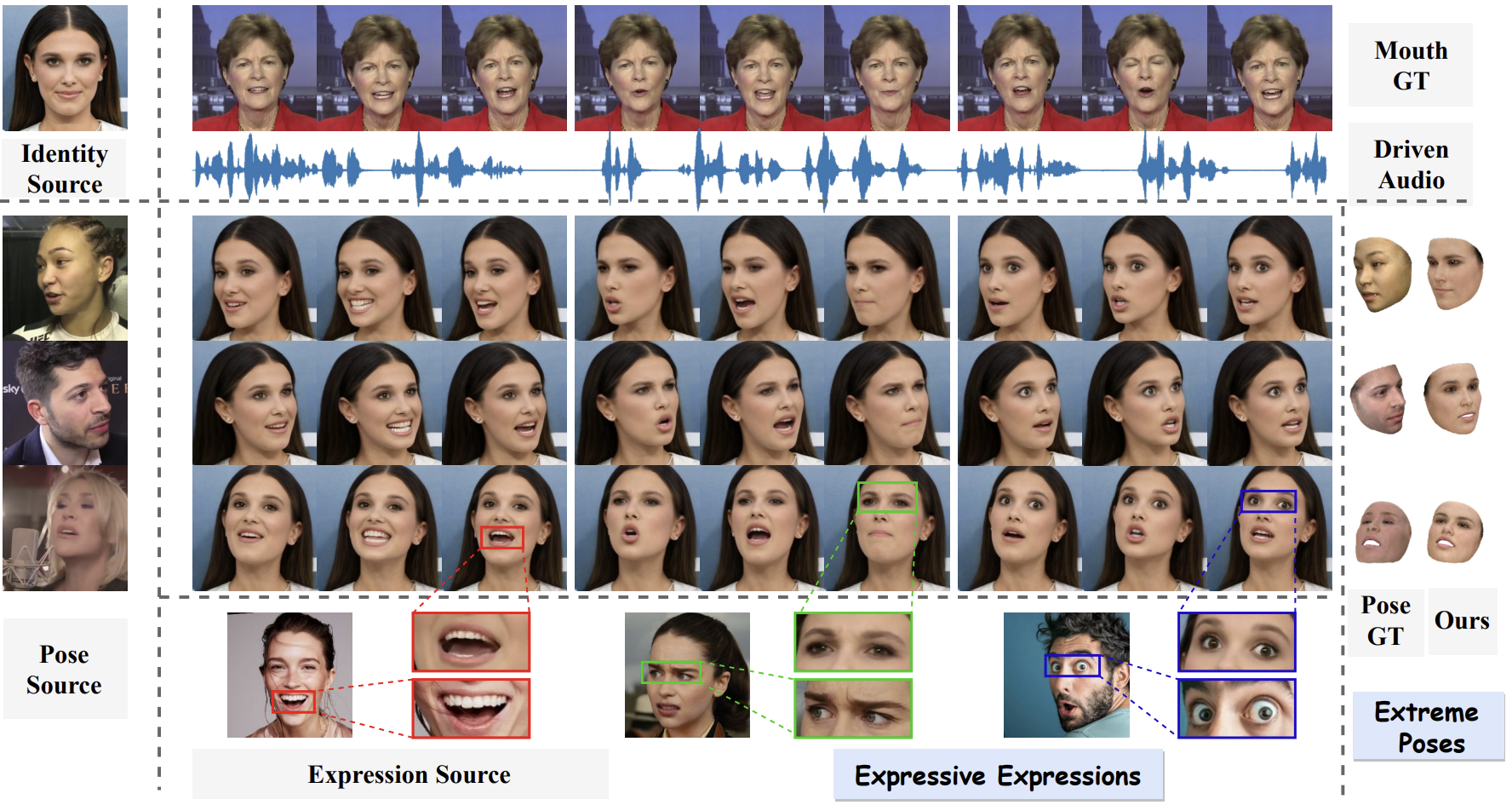
FixTalk: Taming Identity Leakage for High-Quality Talking Head Generation in Extreme Cases
Shuai Tan, Bill Gong, Bin Ji, Ye Pan
- Talking head generation is gaining significant importance across various domains, with a growing demand for high-quality rendering. However, existing methods often suffer from identity leakage (IL) and rendering artifacts (RA), particularly in extreme cases. Through an in-depth analysis of previous approaches, we identify two key insights: (1) IL arises from identity information embedded within motion features, and (2) this identity information can be leveraged to address RA. Building on these findings, this paper introduces FixTalk, a novel framework designed to simultaneously resolve both issues for high-quality talking head generation. Firstly, we propose an Enhanced Motion Indicator (EMI) to effectively decouple identity information from motion features, mitigating the impact of IL on generated talking heads. To address RA, we introduce an Enhanced Detail Indicator (EDI), which utilizes the leaked identity information to supplement missing details, thus fixing the artifacts. Extensive experiments demonstrate that FixTalk effectively mitigates IL and RA, achieving superior performance compared to state-of-the-art methods.
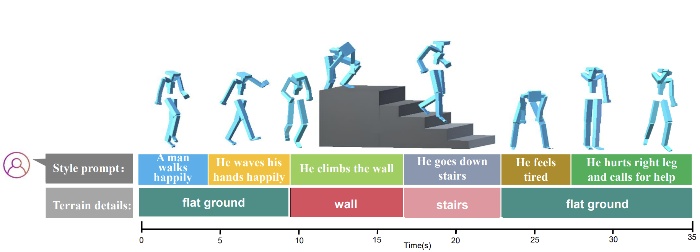
Sport: From zero-shot prompts to real-time motion generation
Bin Ji, Ye Pan, Zhimeng Liu, Shuai Tan, Xiaokang Yang
- Real-time motion generation has garnered significant attention within the fields of computer animation and gaming. Existing methods typically realize motion control via isolated style or content labels, resulting in short, simply motion clips. In this paper, we propose a motion generation framework, called SPORT (“from zero-Shot Prompt tO Real-Time motion generation”), for generating real-time and ever-changing motions using zero-shot prompts. SPORT consists of three primary components: (1) a body-part phase autoencoder that ensures smooth transitions between diverse motions; (2) a body-part content encoder that mitigates semantic gap between texts and motions; (3) a diffusion-based decoder that accelerates the denoising process while enhancing the diversity and realism of motions. Moreover, we develop a prototype for real-time application in Unity, demonstrating that our approach effectively considering the semantic gap caused by abstract style texts and rapidly changing terrains. Through qualitative and quantitative comparisons, we show that SPORT outperforms other approaches in terms of motion quality, style diversity and inference speed.

Vasa-rig: Audio-driven 3d facial animation with ‘live’mood dynamics in virtual reality
Ye Pan, Chang Liu, Sicheng Xu, Shuai Tan, Jiaolong Yang
-
Audio-driven 3D facial animation is crucial for enhancing the metaverse’s realism, immersion, and interactivity. While most existing methods focus on generating highly realistic and lively 2D talking head videos by leveraging extensive 2D video datasets these approaches work in pixel space and are not easily adaptable to 3D environments. We present VASA-Rig, which has achieved a significant advancement in the realism of lip-audio synchronization, facial dynamics, and head movements. In particular, we introduce a novel rig parameter-based emotional talking face dataset and propose the Latents2Rig model, which facilitates the transformation of 2D facial animations into 3D. Unlike mesh-based models, VASA-Rig outputs rig parameters, instantiated in this paper as 174 Metahuman rig parameters, making it more suitable for integration into industry-standard pipelines. Extensive experimental results demonstrate that our approach significantly outperforms existing state-of-the-art methods in terms of both realism and accuracy.
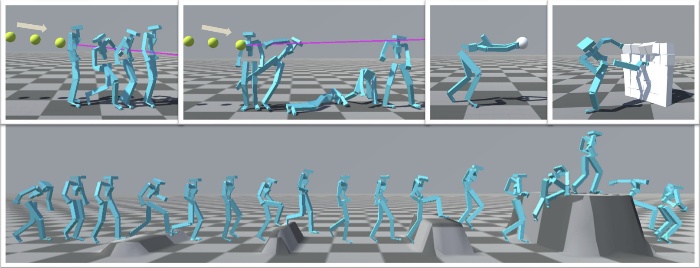
POMP: Physics-consistent Motion Generative Model through Phase Manifolds
Bin Ji, Ye Pan, Zhimeng Liu, Shuai Tan, Xiaogang Jin, Xiaokang Yang
- Numerous researches on real-time motion generation primarily focus on kinematic aspects, often resulting in physically implausible outcomes. In this paper, we present POMP (“Physics-cOnsistent Human Motion Prior through Phase Manifolds”), a novel kinematics-based framework that synthesizes physically consistent motions by leveraging phase manifolds to align motion priors with physics constraints. POMP operates as a frame-by-frame autoregressive model with three core components: a diffusion-based kinematic module, a simulation-based dynamic module, and a phase encoding module. At each timestep, the kinematic module generates an initial target pose, which is subsequently refined by the dynamic module to simulate human-environment interactions. Although the physical simulation ensures adherence to physical laws, it may compromise the kinematic rationality of the posture. Consequently, directly using the simulated result for subsequent frame prediction may lead to cumulative errors. To address this, the phase encoding module performs semantic alignment in the phase manifold. Moreover, we present a pipeline in Unity for generating terrain maps and capturing full-body motion impulses from existing motion capture (MoCap) data. The collected terrain topology and motion impulse data facilitate the training of POMP, enabling it to robustly respond to underlying contactforces and applied dynamics. Extensive evaluations demonstrate the efficacy of POMP across various contexts, terrains, and physical interactions.
AniArtAvatar: Animatable 3D art avatar from a single image
Shaoxu Li, Ye Pan
- We present a novel approach for generating animatable 3D-aware art avatars from a single image, with controllable facial expressions, head poses, and shoulder movements. Unlike previous reenactment methods, our approach utilizes a pre-trained view-conditioned 2D diffusion model to synthesize multi-view images from a single art portrait with a neutral expression. With the generated colors and normals, we synthesize a static avatar using an SDF-based neural surface. For avatar animation, we extract control points, transfer the motion with these points, and deform the implicit canonical space. Firstly, we render the front image of the avatar, extract the 2D landmarks, and project them to the 3D space using a trained SDF network. We extract 3D driving landmarks using 3DMM and transfer the motion to the avatar landmarks. We deform the SDF-based neural surface utilizing neutral and expressive 3D avatar landmarks to animate the expression. To animate the avatar pose, we manually set the body height and bound the head and torso of an avatar with two cages. The head and torso can be animated by transforming the two cages. Our approach is a one-shot pipeline that can be applied to various styles. Experiments demonstrate that our method can generate high-quality 3D art avatars with desired control over different motions.

Edtalk: Efficient disentanglement for emotional talking head synthesis
Shuai Tan, Bin Ji, Mengxiao Bi, Ye Pan
- Achieving disentangled control over multiple facial motions and accommodating diverse input modalities greatly enhances the application and entertainment of the talking head generation. This necessitates a deep exploration of the decoupling space for facial features, ensuring that they a) operate independently without mutual interference and b) can be preserved to share with different modal inputs-both aspects often neglected in existing methods. To address this gap, this paper proposes a novel Efficient Disentanglement framework for Talking head generation (EDTalk). Our framework enables individual manipulation of mouth shape, head pose, and emotional expression, conditioned on video or audio inputs. Specifically, we employ three lightweight modules to decompose the facial dynamics into three distinct latent spaces representing mouth, pose, and expression, respectively. Each space is characterized by a set of learnable bases whose linear combinations define specific motions. To ensure independence and accelerate training, we enforce orthogonality among bases and devise an efficient training strategy to allocate motion responsibilities to each space without relying on external knowledge. The learned bases are then stored in corresponding banks, enabling shared visual priors with audio input. Furthermore, considering the properties of each space, we propose an Audio-to-Motion module for audio-driven talking head synthesis. Experiments are conducted to demonstrate the effectiveness of EDTalk. The code and pretrained models are released at: https://tanshuai0219.github.io/EDTalk/
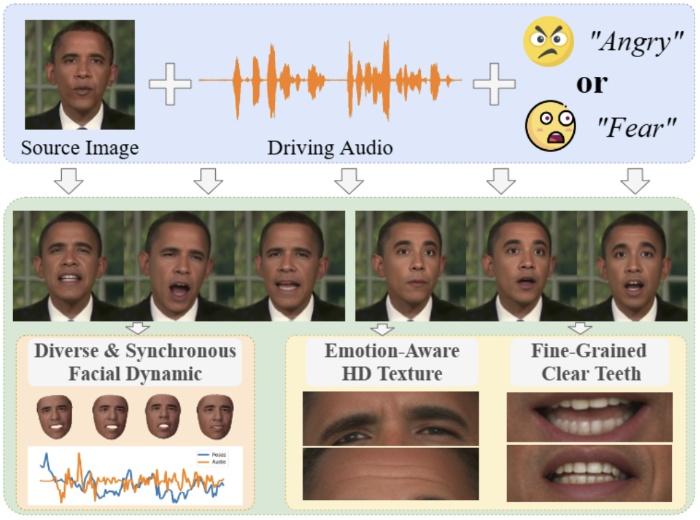
Shuai Tan, Bin Ji, Ye Pan
- Generating emotional talking faces is a practical yet challenging endeavor. To create a lifelike avatar we draw upon two critical insights from a human perspective: 1) The connection between audio and the non-deterministic facial dynamics encompassing expressions blinks poses should exhibit synchronous and one-to-many mapping. 2) Vibrant expressions are often accompanied by emotion-aware high-definition (HD) textures and finely detailed teeth. However both aspects are frequently overlooked by existing methods. To this end this paper proposes using normalizing Flow and Vector-Quantization modeling to produce emotional talking faces that satisfy both insights concurrently (FlowVQTalker). Specifically we develop a flowbased coefficient generator that encodes the dynamics of facial emotion into a multi-emotion-class latent space represented as a mixture distribution. The generation process commences with random sampling from the modeled distribution guided by the accompanying audio enabling both lip-synchronization and the uncertain nonverbal facial cues generation. Furthermore our designed vector-quantization image generator treats the creation of expressive facial images as a code query task utilizing a learned codebook to provide rich high-quality textures that enhance the emotional perception of the results. Extensive experiments are conducted to showcase the effectiveness of our approach.

Style2talker: High-resolution talking head generation with emotion style and art style
Shuai Tan, Bin Ji, Ye Pan
- Although automatically animating audio-driven talking heads has recently received growing interest, previous efforts have mainly concentrated on achieving lip synchronization with the audio, neglecting two crucial elements for generating expressive videos: emotion style and art style. In this paper, we present an innovative audio-driven talking face generation method called Style2Talker. It involves two stylized stages, namely Style-E and Style-A, which integrate text-controlled emotion style and picture-controlled art style into the final output. In order to prepare the scarce emotional text descriptions corresponding to the videos, we propose a labor-free paradigm that employs large-scale pretrained models to automatically annotate emotional text labels for existing audio-visual datasets. Incorporating the synthetic emotion texts, the Style-E stage utilizes a large-scale CLIP model to extract emotion representations, which are combined with the audio, serving as the condition for an efficient latent diffusion model designed to produce emotional motion coefficients of a 3DMM model. Moving on to the Style-A stage, we develop a coefficient-driven motion generator and an art-specific style path embedded in the well-known StyleGAN. This allows us to synthesize high-resolution artistically stylized talking head videos using the generated emotional motion coefficients and an art style source picture. Moreover, to better preserve image details and avoid artifacts, we provide StyleGAN with the multi-scale content features extracted from the identity image and refine its intermediate feature maps by the designed content encoder and refinement network, respectively. Extensive experimental results demonstrate our method outperforms existing state-of-the-art methods in terms of audio-lip synchronization and performance of both emotion style and art style.
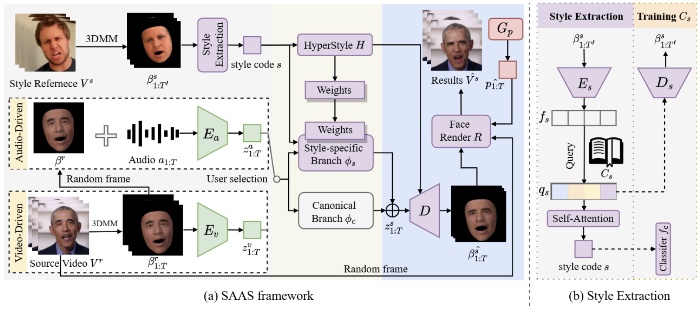
Shuai Tan, Bin Ji, Yu Ding, Ye Pan
- Generating stylized talking head with diverse head motions is crucial for achieving natural-looking videos but still remains challenging. Previous works either adopt a regressive method to capture the speaking style, resulting in a coarse style that is averaged across all training data, or employ a universal network to synthesize videos with different styles which causes suboptimal performance. To address these, we propose a novel dynamic-weight method, namely Say Anything with Any Style (SAAS), which queries the discrete style representation via a generative model with a learned style codebook. Specifically, we develop a multi-task VQ-VAE that incorporates three closely related tasks to learn a style codebook as a prior for style extraction. This discrete prior, along with the generative model, enhances the precision and robustness when extracting the speaking styles of the given style clips. By utilizing the extracted style, a residual architecture comprising a canonical branch and style-specific branch is employed to predict the mouth shapes conditioned on any driving audio while transferring the speaking style from the source to any desired one. To adapt to different speaking styles, we steer clear of employing a universal network by exploring an elaborate HyperStyle to produce the style-specific weights offset for the style branch. Furthermore, we construct a pose generator and a pose codebook to store the quantized pose representation, allowing us to sample diverse head motions aligned with the audio and the extracted style. Experiments demonstrate that our approach surpasses state-of-the-art methods in terms of both lip-synchronization and stylized expression. Besides, we extend our SAAS to video-driven style editing field and achieve satisfactory performance as well.
Ye Pan, Shuai Tan, Shengran Cheng, Qunfen Lin, Zijiao Zeng, Kenny Mitchell
- Stylized avatars are common virtual representations used in VR to support interaction and communication between remote collaborators. However, explicit expressions are notoriously difficult to create, mainly because most current methods rely on geometric markers and features modeled for human faces, not stylized avatar faces. To cope with the challenge of emotional and expressive generating talking avatars, we build the Emotional Talking Avatar Dataset which is a talking-face video corpus featuring 6 different stylized characters talking with 7 different emotions. Together with the dataset, we also release an emotional talking avatar generation method which enables the manipulation of emotion. We validated the effectiveness of our dataset and our method in generating audio based puppetry examples, including comparisons to state-of-the-art techniques and a user study. Finally, various applications of this method are discussed in the context of animating avatars in VR.
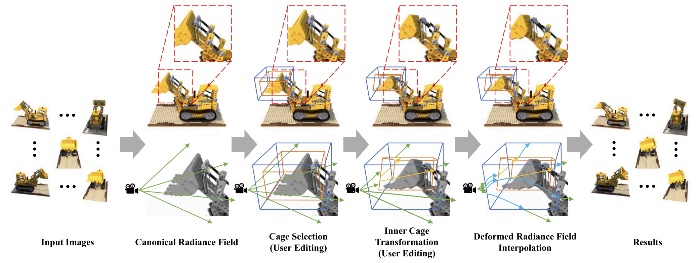
Interactive geometry editing of neural radiance fields
Shaoxu Li, Ye Pan
- Neural Radiance Fields (NeRF) have recently emerged as a promising approach for synthesizing highly realistic images from 3D scenes. This technology has shown impressive results in capturing intricate details and producing photorealistic renderings. However, one of the limitations of traditional NeRF approaches is the difficulty in editing and manipulating the geometry of the scene once it has been captured. This restriction hinders creative freedom and practical applicability. In this paper, we propose a method that enables interactive geometry editing for neural radiance fields manipulation. We use two proxy cages (inner cage and outer cage) to edit a scene. The inner cage defines the operation target, and the outer cage defines the adjustment space. Various operations apply to the two cages. After cage selection, operations on the inner cage lead to the desired transformation of the inner cage and adjustment of the outer cage. Users can edit the scene with translation, rotation, scaling, or combinations. The operations on the corners and edges of the cage are also supported. Our method does not need any explicit 3D geometry representations. The interactive geometry editing applies directly to the implicit neural radiance fields. Extensive experimental results demonstrate the effectiveness of our approach.

Hyperstyle3d: Text-guided 3d portrait stylization via hypernetworks
Zhuo Chen, Xudong Xu, Yichao Yan, Ye Pan, Wenhan Zhu, Wayne Wu, Bo Dai, Xiaokang Yang
- Portrait stylization is a long-standing task enabling extensive applications. Although 2D-based methods have made great progress in recent years, real-world applications such as metaverse and games often demand 3D content. On the other hand, the requirement of 3D data, which is costly to acquire, significantly impedes the development of 3D portrait stylization methods. In this paper, inspired by the success of 3D-aware GANs that bridge 2D and 3D domains with 3D fields as the intermediate representation for rendering 2D images, we propose a novel method, dubbed HyperStyle3D, based on 3D-aware GANs for 3D portrait stylization. At the core of our method is a hyper-network learned to manipulate the parameters of the generator in a single forward pass. It not only offers a strong capacity to handle multiple styles with a single model, but also enables flexible fine-grained stylization that affects only texture, shape, or local part of the portrait. While the use of 3D-aware GANs bypasses the requirement of 3D data, we further alleviate the necessity of style images with the CLIP model being the style guidance. We conduct an extensive set of experiments across the style, attribute, and shape, and meanwhile, measure the 3D consistency. These experiments demonstrate the superior capability of our HyperStyle3D model in rendering 3D-consistent images in diverse styles, deforming the face shape, and editing various attributes. Our project page: https://windlikestone.github.io/HyperStyle3D-website/.

EmoFace: Audio-driven emotional 3D face animation
Chang Liu, Qunfen Lin, Zijiao Zeng, Ye Pan
- Audio-driven emotional 3D face animation aims to generate emotionally expressive talking heads with synchronized lip movements. However, previous research has often overlooked the influence of diverse emotions on facial expressions or proved unsuitable for driving MetaHuman models. In response to this deficiency, we introduce EmoFace, a novel audio-driven methodology for creating facial animations with vivid emotional dynamics. Our approach can generate facial expressions with multiple emotions, and has the ability to generate random yet natural blinks and eye movements, while maintaining accurate lip synchronization. We propose independent speech encoders and emotion encoders to learn the relationship between audio, emotion and corresponding facial controller rigs, and finally map into the sequence of controller values. Additionally, we introduce two post-processing techniques dedicated to enhancing the authenticity of the animation, particularly in blinks and eye movements. Furthermore, recognizing the scarcity of emotional audio-visual data suitable for MetaHuman model manipulation, we contribute an emotional audio-visual dataset and derive control parameters for each frames. Our proposed methodology can be applied in producing dialogues animations of non-playable characters (NPCs) in video games, and driving avatars in virtual reality environments. Our further quantitative and qualitative experiments, as well as an user study comparing with existing researches show that our approach demonstrates superior results in driving 3D facial models. The code and sample data are available at https://github.com/SJTU-Lucy/EmoFace
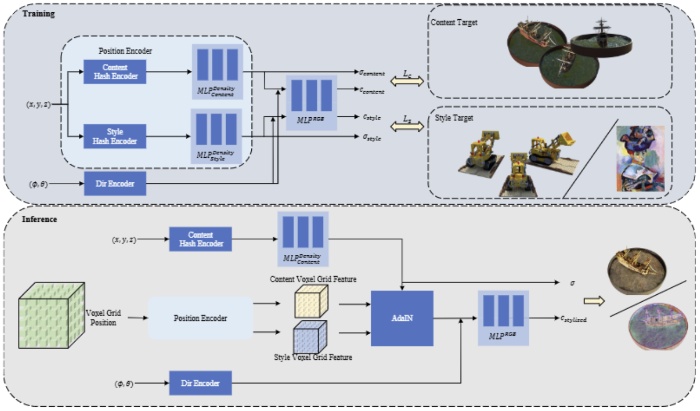
Instant photorealistic neural radiance fields stylization
Shaoxu Li, Ye Pan
- We present Instant Photorealistic Neural Radiance Fields Stylization, a novel approach for multi-view image stylization for the 3D scene. Our approach models a neural radiance field based on neural graphics primitives, which use a hash table-based position encoder for position embedding. We split the position encoder into two parts, the content and style sub-branches, and train the network for normal novel view image synthesis with the content and style targets. In the inference stage, we execute AdaIN to the output features of the position encoder, with content and style voxel grid features as reference. The stylization of novel view images could be obtained with the adjusted features. Given a set of images of 3D scenes and a style target(a style image or another set of 3D scenes), our method can generate stylized novel views with a consistent appearance at various view angles in less than 10 minutes on modern GPU hardware.
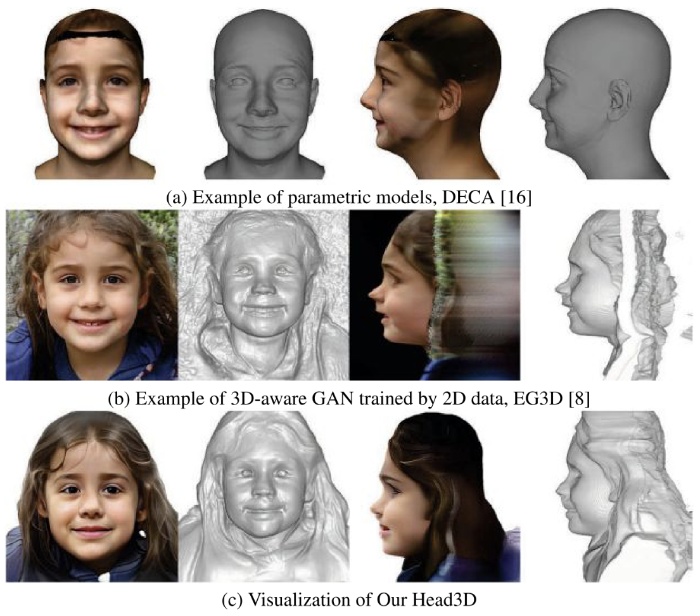
Head3d: Complete 3d head generation via tri-plane feature distillation
Yuhao Cheng, Yichao Yan, Wenhan Zhu, Ye Pan, Bowen Pan, Xiaokang Yang
- Head generation with diverse identities is an important task in computer vision and computer graphics, widely used in multimedia applications. However, current full-head generation methods require a large number of three-dimensional (3D) scans or multi-view images to train the model, resulting in expensive data acquisition costs. To address this issue, we propose Head3D, a method to generate full 3D heads with limited multi-view images. Specifically, our approach first extracts facial priors represented by tri-planes learned in EG3D, a 3D-aware generative model, and then proposes feature distillation to deliver the 3D frontal faces within complete heads without compromising head integrity. To mitigate the domain gap between the face and head models, we present a dual-discriminator to guide the frontal and back head generation. Our model achieves cost-efficient and diverse complete head generation with photo-realistic renderings and high-quality geometry representations. Extensive experiments demonstrate the effectiveness of our proposed Head3D, both qualitatively and quantitatively.
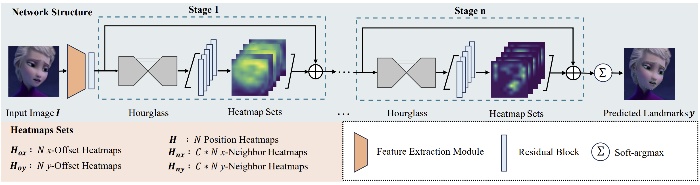
StylizedFacePoint: Facial Landmark Detection for Stylized Characters
Shengran Cheng, Chuhang Ma, Ye Pan
- Facial landmark detection forms the foundation for numerous face-related tasks. Recently, this field has gained substantial attention and made significant advancements. Nonetheless, detecting facial landmarks for stylized characters still remains a challenge. Existing approaches, which are mostly trained on real-human face datasets, struggle to perform well due to the structural variations between real and stylized characters. Additionally, a comprehensive dataset for analyzing stylized characters’ facial features is lacking. This study proposes a novel dataset, the Facial Landmark Dataset for Stylized Characters (FLSC), which contains 2674 images and 4086 faces selected from 16 cartoon video clips, together with 98 landmarks per image, labeled by professionals. Besides, we propose StylizedFacePoint: a deep-learning-based method for stylized facial landmark detection that outperforms the existing approaches. This method has also proven to work well for characters with styles outside the training domain. Moreover, we outline two primary types of applications for our dataset and method. For each, we provide a detailed illustrative example.

Emmn: Emotional motion memory network for audio-driven emotional talking face generation
Shuai Tan, Bin Ji, Ye Pan
- Synthesizing expression is essential to create realistic talking faces. Previous works consider expressions and mouth shapes as a whole and predict them solely from audio inputs. However, the limited information contained in audio, such as phonemes and coarse emotion embedding, may not be suitable as the source of elaborate expressions. Besides, since expressions are tightly coupled to lip motions, generating expression from other sources is tricky and always neglects expression performed on mouth region, leading to inconsistency between them. To tackle the issues, this paper proposes Emotional Motion Memory Net (EMMN) that synthesizes expression overall on the talking face via emotion embedding and lip motion instead of the sole audio. Specifically, we extract emotion embedding from audio and design Motion Reconstruction module to decompose ground truth videos into mouth features and expression features before training, where the latter encode all facial factors about expression. During training, the emotion embedding and mouth features are used as keys, and the corresponding expression features are used as values to create key-value pairs stored in the proposed Motion Memory Net. Hence, once the audio-relevant mouth features and emotion embedding are individually predicted from audio at inference time, we treat them as a query to retrieve the best-matching expression features, performing expression overall on the face and thus avoiding inconsistent results. Extensive experiments demonstrate that our method can generate high-quality talking face videos with accurate lip movements and vivid expressions on unseen subjects.

Ye Pan, Ruisi Zhang, Shengran Cheng, Shuai Tan, Yu Ding, Kenny Mitchell, Xubo Yang
- The paper presents emotional voice puppetry, an audio-based facial animation approach to portray characters with vivid emotional changes. The lips motion and the surrounding facial areas are controlled by the contents of the audio, and the facial dynamics are established by category of the emotion and the intensity. Our approach is exclusive because it takes account of perceptual validity and geometry instead of pure geometric processes. Another highlight of our approach is the generalizability to multiple characters. The findings showed that training new secondary characters when the rig parameters are categorized as eye, eyebrows, nose, mouth, and signature wrinkles is significant in achieving better generalization results compared to joint training. User studies demonstrate the effectiveness of our approach both qualitatively and quantitatively. Our approach can be applicable in AR/VR and 3DUI, namely, virtual reality avatars/self-avatars, teleconferencing and in-game dialogue.
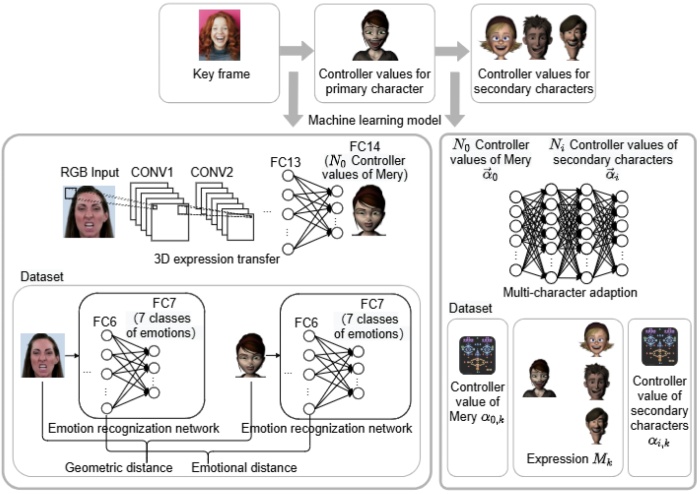
Real-time facial animation for 3d stylized character with emotion dynamics
Ye Pan, Ruisi Zhang, Jingying Wang, Yu Ding, Kenny Mitchell
- Our aim is to improve animation production techniques’ efficiency and effectiveness. We present two real-time solutions which drive character expressions in a geometrically consistent and perceptually valid way. Our first solution combines keyframe animation techniques with machine learning models. We propose a 3D emotion transfer network makes use of a 2D human image to generate a stylized 3D rig parameter. Our second solution combines blendshape-based motion capture animation techniques with machine learning models. We propose a blendshape adaption network which generates the character rig parameter motions with geometric consistency and temporally stability. We demonstrate the effectiveness of our system by comparing it to a commercial product Faceware. Results reveal that ratings of the recognition, intensity, and attractiveness of expressions depicted for animated characters via our systems are statistically higher than Faceware. Our results may be implemented into the animation pipeline, supporting animators to create expressions more rapidly and precisely.
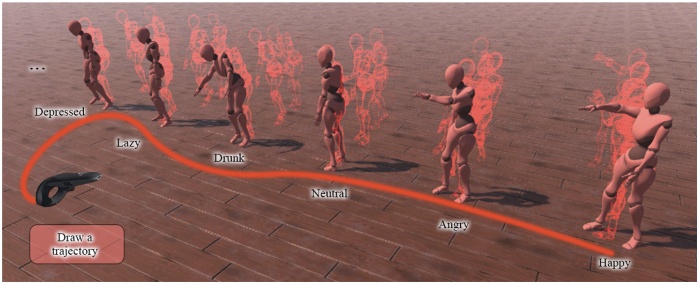
Stylevr: Stylizing character animations with normalizing flows
Bin Ji, Ye Pan, Yichao Yan, Ruizhao Chen, Xiaokang Yang
- The significance of artistry in creating animated virtual characters is widely acknowledged, and motion style is a crucial element in this process. There has been a long-standing interest in stylizing character animations with style transfer methods. However, this kind of models can only deal with short-term motions and yield deterministic outputs. To address this issue, we propose a generative model based on normalizing flows for stylizing long and aperiodic animations in the VR scene. Our approach breaks down this task into two sub-problems: motion style transfer and stylized motion generation, both formulated as the instances of conditional normalizing flows with multi-class latent space. Specifically, we encode high-frequency style features into the latent space for varied results and control the generation process with style-content labels for disentangled edits of style and content. We have developed a prototype, StyleVR, in Unity, which allows casual users to apply our method in VR. Through qualitative and quantitative comparisons, we demonstrate that our system outperforms other methods in terms of style transfer as well as stochastic stylized motion generation.
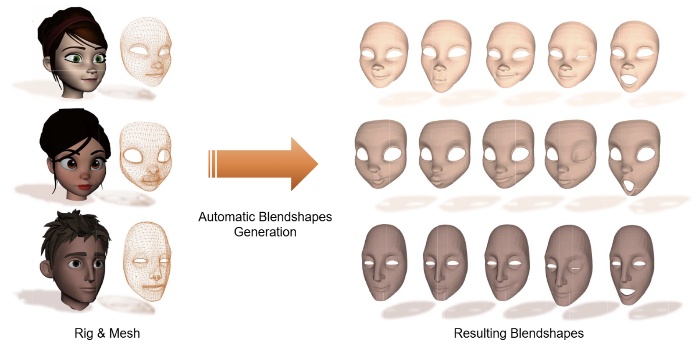
Fully Automatic Blendshape Generation for Stylized Characters
Jingying Wang, Yilin Qiu, Keyu Chen, Yu Ding, Ye Pan
- Avatars are one of the most important elements in virtual environments. Real-time facial retargeting technology is of vital importance in AR/VR interactions, the filmmaking, and the entertainment industry, and blendshapes for avatars are one of its important materials. Previous works either focused on the characters with the same topology, which cannot be generalized to universal avatars, or used optimization methods that have high demand on the dataset. In this paper, we adopt the essence of deep learning and feature transfer to realize deformation transfer, thereby generating blendshapes for target avatars based on the given sources. We proposed a Variational Autoencoder (VAE) to extract the latent space of the avatars and then use a Multilayer Perceptron (MLP) model to realize the translation between the latent spaces of the source avatar and target avatars. By decoding the latent code of different blendshapes, we can obtain the blendshapes for the target avatars with the same semantics as that of the source. We qualitatively and quantitatively compared our method with both classical and learning-based methods. The results revealed that the blendshapes generated by our method achieves higher similarity to the groundtruth blendshapes than the state-of-art methods. We also demonstrated that our method can be applied to expression transfer for stylized characters with different topologies.
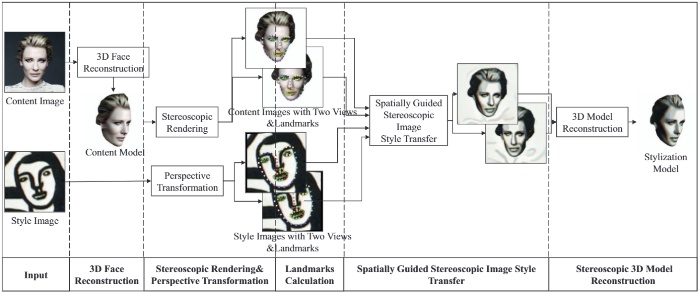
Rendering and Reconstruction Based 3D Portrait Stylization
Shaoxu Li, Ye Pan
- Both 2D images and 3D models are vital aspects of portrait applications. Existing style transfer methods principally emphasized 2D images, neglecting the urge for 3D style transfer. We propose rendering and reconstruction based 3D portrait stylization. And we present the first geometry-aware stereoscopic image stylization. Our framework requires one content image and one style image to obtain a 3D stylization portrait. In the first step, 3D face reconstruction produces a 3D face model. We excute stereoscopic rendering to the model and reserve the images and parameters. We propose to perform the perspective transformation on one style image to match two content images. Then we use disparity loss to conduct a geometry-aware stereoscopic stylization. Using stereoscopic stylization images, we calculate the 3D stylization portrait using a stereoscopic 3D reconstruction algorithm. Expect for portraits, the framework applies to models with simple shapes. Extensive experiments demonstrate the validity and robustness of our method.

Double Doodles: Sketching Animation in Immersive Environment With 3+ 6 DOFs Motion Gestures
Ruizhao Chen, Ye Pan, Zhigang Deng, Lili Wang, Lizhuang Ma
- We present “Double Doodles’’ to make full use of two sequential inputs of a VR controller with 9 DOFs in total, 3 DOFs of the first input sequence for the generation of motion paths and 6 DOFs of the second input sequence for motion gestures. While engineering our system, we take ergonomics into consideration and design a set of user-defined motion gestures to describe character motions. We employ a real-time deep learning-based approach for highly accurate motion gesture classification. We then integrate our approach into a prototype system, and it allows users to directly create character animations in VR environments using motion gestures with a VR controller, followed by animation preview and animation interactive editing. Finally, we evaluate the feasibility and effectiveness of our system through a user study, demonstrating the usefulness of our system for visual storytelling dedicated to amateurs, as well as for providing fast drafting tools for artists.

State of the Art in Telepresence (Part 1)
Jason Lawrence, Ye Pan, Dan B Goldman, Rachel McDonnell, Carol O’Sullivan, Dave Luebke, Koki Nagano, Michael Zollhoefer, Jason Saragih
- the use of virtual reality technology, especially for remote control of machinery or for apparent participation in distant events
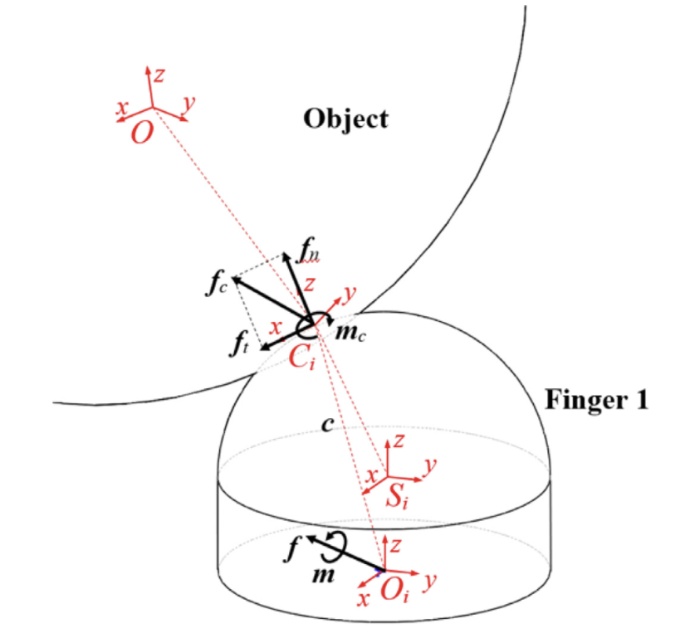
Enabling massage actions: An interactive parallel robot with compliant joints
Huixu Dong, Yue Feng, Chen Qiu, Ye Pan, Miao He, I-Ming Chen
- We propose a parallel massage robot with compliant joints based on the series elastic actuator (SEA), offering a unified force-position control approach. First, the kinematic and static force models are established for obtaining the corresponding control variables. Then, a novel force-position control strategy is proposed to separately control the force-position along the normal direction of the surface and another two-direction displacement, without the requirement of a robotic dynamics model. To evaluate its performance, we implement a series of robotic massage experiments. The results demonstrate that the proposed massage manipulator can successfully achieve desired forces and motion patterns of massage tasks, arriving at a high-score user experience.
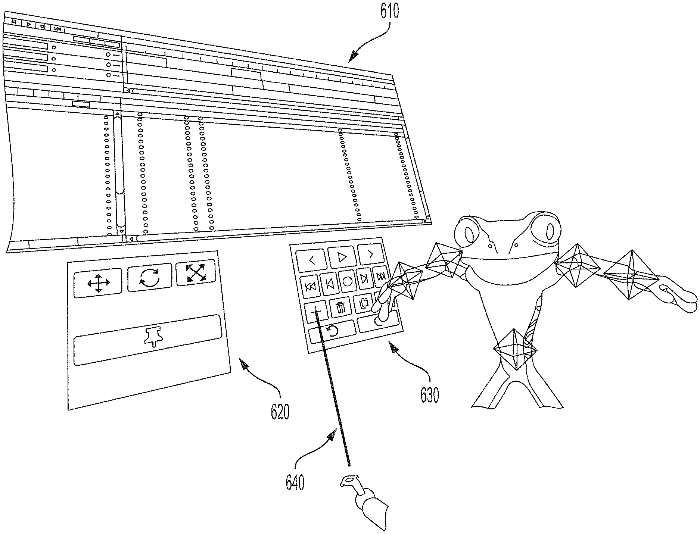
Augmenting a physical object with virtual components
Corey D Drake, Kenneth J Mitchell, Rachel E Rodgers, Joseph G Hager IV, Kyna P McIntosh, Ye Pan
- Systems and methods are presented for immersive and simultaneous animation in a mixed reality environment. Techniques disclosed represent a physical object, present at a scene, in a 3D space of a virtual environment associated with the scene. A virtual element is posed relative to the representation of the physical object in the virtual environ ment. The virtual element is displayed to users from a perspective of each user in the virtual environment. Respon sive to an interaction of one user with the virtual element, an edit command is generated and the pose of the virtual element is adjusted in the virtual environment according to the edit command. The display of the virtual element to the users is then updated according to the adjusted pose. When simultaneous and conflicting edit commands are generated by collaborating users, policies to reconcile the conflicting edit commands are disclosed.

MienCap: Performance-based facial animation with live mood dynamics
Ye Pan, Ruisi Zhang, Jingying Wang, Nengfu Chen, Yilin Qiu, Yu Ding, Kenny Mitchell
- Our purpose is to improve performance-based animation which can drive believable 3D stylized characters that are truly perceptual. By combining traditional blendshape animation techniques with machine learning models, we present a real time motion capture system, called MienCap, which drive character expressions in a geometrically consistent and perceptually valid way. We demon-strate the effectiveness of our system by comparing to a commercial product Faceware. Results reveal that ratings of the recognition of expressions depicted for animated characters via our systems are statistically higher than Faceware. Our results may be implemented into the VR filmmaking and animation pipeline, and provide animators with a system for creating the expressions they wish to use more quickly and accurately.
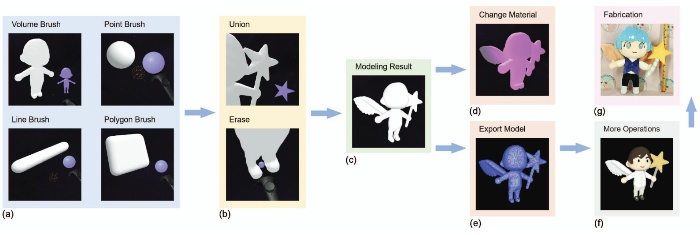
3DBrushVR: From Virtual Reality Primitives to Complex Manifold Objects
Yuzhen Zhu, Xiangjun Tang, Jing Zhang, Ye Pan, Jingjing Shen, Xiaogang Jin
- SurfaceBrush and Brush2Model are two systems which enable users to create 3D objects intuitively using a hand-held controller in virtual reality (VR). These state-of-the-art methods either start modeling from dense collections of stroke ribbons drawn by professional artists, or from the most basic point skeletons, line skeletons, and polygon skeletons. Thus, it is very challenging for novices and amateurs to design complex models efficiently. We propose 3D-BrushVR, a novel VR modeling tool that uses volume skeleton-based convolution surfaces. It enables the user to draw with arbitrarily shaped brushes and generate 3D manifold objects by fusing the brushed primitives. Unlike existing VR drawing and modeling tools, our approach can directly take some common but complex objects as primitives, and assemble them using implicit surfaces, thus providing a more flexible and powerful modeling ability. To achieve real-time performance, we introduce a new GPU-based method to calculate the volume fields of the resulting convolution surfaces. We also introduce several specially designed time-varying shaders to render the designed model for a better and more appealing modeling experience. We demonstrate the usability and modeling ability of our 3DBrushVR interface by comparing it with the state-of-the-art methods in an observational study. Experimental results further validate the effectiveness and flexibility of our approach.

State of the art in telepresence
Jason Lawrence, Ye Pan, Dan B Goldman, Rachel McDonnell, Julie Robillard, Carol O’Sullivan, Yaser Sheikh, Michael Zollhoefer, Jason Saragih
- Welcome everybody! I am Michael a Research Scientist from Reality Labs Research in Pittsburgh. Today, I want to talk about “Complete Codec Telepresence”, how this is related to the concept of the “Trinity of Telepresence”, and provide you with a deep dive into our technology to render photorealistic avatars and spaces.
Stylized Avatar Animation Based on Deep Learning
Ruisi Zhang, Ye Pan
- Animating 3D character rigs from human faces requires both geometry features and facial expression information.However,traditional animation approaches such as ARkit failed to connect character storytelling to the audience because the character expressions are hard to recognize.However,recent emotion-based motion capture techniques,such as ExprGen,consider using facial emotion for facial capture.But it is difficult to characterize the details of the character’s face.A network is proposed to incorporate facial expressions into animation.Firstly,an emotion recognition neural network is used to match human and character datasets.Then,an end-to-end neural network is trained to extract character facial expressions and transfer rig parameters to characters.Finally,human face geometry is utilized to refine rig parameters.Qualitative analysis of the generated character expressions,and quantitative analysis of the attractiveness and intensity of the character expression have demonstrated the accuracy and real-time of the model.

Hpof: 3d human pose recovery from monocular video with optical flow
Bin Ji, Chen Yang, Yao Shunyu, Ye Pan
- This paper introduces HPOF, a novel deep neural network to reconstruct the 3D human motion from a monocular video. Recently, model-based methods have been proposed to simplify the reconstruction task by estimating several parameters that control a deformable surface model to fit the person in the image. However, learning the parameters from a single image is a highly ill-posed problem, and the process is ultimately data-hungry. Existing 3D datasets are not sufficient, and the usage of 2D in-the-wild datasets is often susceptible to the inadequate precision of manual annotations. To address the above issues, our method yields substantial improvements in two domains. First, we leverage optical flow to supervise the 2D rendered images of predicted SMPL models to learn short-term temporal features. Besides, taking long-term temporal consistency into account, we define a novel temporal encoder based on a dilated convolutional network. The encoder decomposes the learning process of human shape and pose, first guarantees the invariance of the body shape, and then simulates a more reasonable forward kinematics process on this basis to achieve more accurate pose estimation. In addition, an adversarial learning framework is applied to supervise the reconstruction progress in a coarse-grained way. We show that HPOF not only improves the accuracy of 3D poses but ensures the realistic body structure throughout the video. We perform extensive experimentation to demonstrate the superiority of our method and analyze the effectiveness of our model, surpassing other state-of-the-arts.
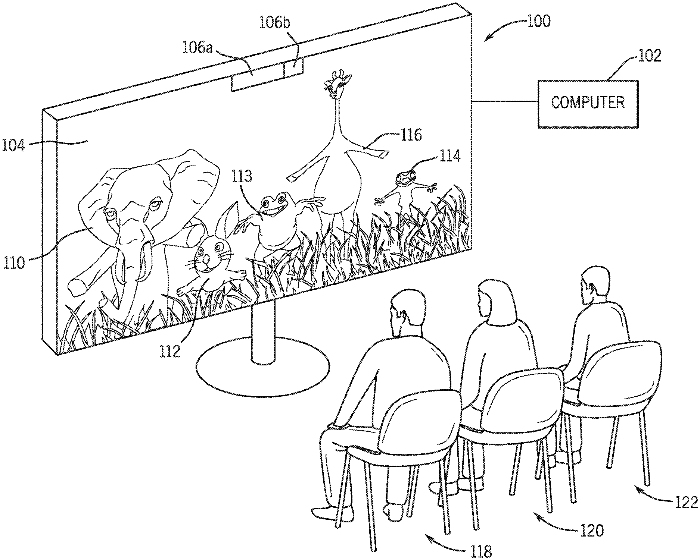
Gaze based rendering for audience engagement
Ye Pan, Kenny Mitchell
- The present disclosure is related to an audience engagement system and method to display images on a display. The method includes detecting a gaze direction of a designated viewer, rendering a gaze object within an image on a gaze axis corresponding to the gaze direction, rendering an audience object within the image on a normal axis corresponding to a display axis, composting the audience object and the gaze object together in a composited image, and displaying the composited image on the display.
.jpg)
Foreward to the Special Section on the Reality-Virtuality Continuum and its Applications (RVCA)
Mashhuda Glencross, Kenny Mitchell, Billinghurst Mark, Ye Pan
- Purpose: To survey soccer practitioners’ recovery strategy:(1) use,(2) perceived effectiveness, and (3) factors influencing their implementation in professional soccer. Methods: A cross-sectional convenience sample of professional soccer club/confe… Read More about The Use of Recovery Strategies in Professional Soccer: A Worldwide Survey.
The rocketbox library and the utility of freely available rigged avatars
Mar Gonzalez-Franco, Eyal Ofek, Ye Pan, Angus Antley, Anthony Steed, Bernhard Spanlang, Antonella Maselli, Domna Banakou, Nuria Pelechano, Sergio Orts-Escolano, Veronica Orvalho, Laura Trutoiu, Markus Wojcik, Maria V Sanchez-Vives, Jeremy Bailenson, Mel Slater, Jaron Lanier
- As part of the open sourcing of the Microsoft Rocketbox avatar library for research and academic purposes, here we discuss the importance of rigged avatars for the Virtual and Augmented Reality (VR, AR) research community. Avatars, virtual representations of humans, are widely used in VR applications. Furthermore many research areas ranging from crowd simulation to neuroscience, psychology, or sociology have used avatars to investigate new theories or to demonstrate how they influence human performance and interactions. We divide this paper in two main parts: the first one gives an overview of the different methods available to create and animate avatars. We cover the current main alternatives for face and body animation as well introduce upcoming capture methods. The second part presents the scientific evidence of the utility of using rigged avatars for embodiment but also for applications such as crowd simulation and entertainment. All in all this paper attempts to convey why rigged avatars will be key to the future of VR and its wide adoption.

PoseMMR: A Collaborative Mixed Reality Authoring Tool for Character Animation
Ye Pan, Kenny Mitchell
- Augmented reality devices enable new approaches for character animation, e.g., given that character posing is three dimensional in nature it follows that interfaces with higher degrees-of-freedom (DoF) should outperform 2D interfaces. We present PoseMMR, allowing Multiple users to animate characters in a Mixed Reality environment, like how a stop-motion animator would manipulate a physical puppet, frame-by-frame, to create the scene. We explore the potential advantages of the PoseMMR can facilitate immersive posing, animation editing, version control and collaboration, and provide a set of guidelines to foster the development of immersive technologies as tools for collaborative authoring of character animation.
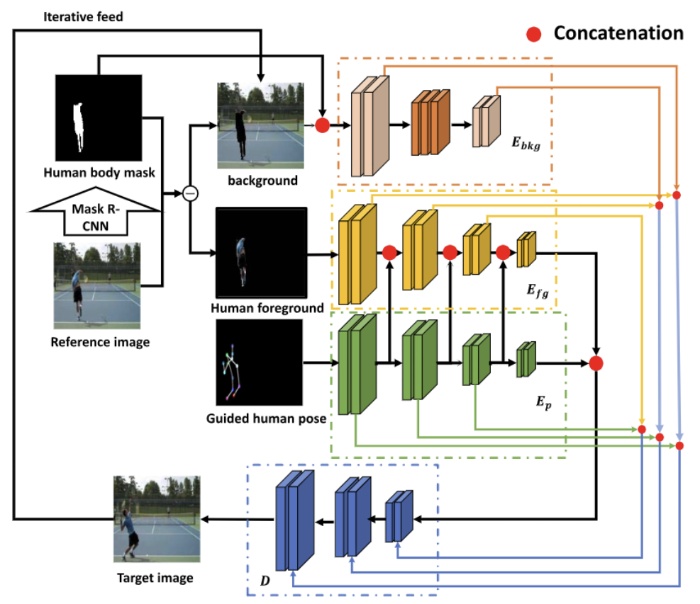
Pose-guided person image synthesis in the non-iconic views
Chengming Xu, Yanwei Fu, Chao Wen, Ye Pan, Yu-Gang Jiang, Xiangyang Xue
- Generating realistic images with the guidance of reference images and human poses is challenging. Despite the success of previous works on synthesizing person images in the iconic views, no efforts are made towards the task of pose-guided image synthesis in the non-iconic views. Particularly, we find that previous models cannot handle such a complex task, where the person images are captured in the non-iconic views by commercially-available digital cameras. To this end, we propose a new framework - Multi-branch Refinement Network (MR-Net), which utilizes several visual cues, including target person poses, foreground person body and scene images parsed. Furthermore, a novel Region of Interest (RoI) perceptual loss is proposed to optimize the MR-Net. Extensive experiments on two non-iconic datasets, Penn Action and BBC-Pose, as well as an iconic dataset - Market-1501, show the efficacy of the proposed model that can tackle the problem of pose-guided person image generation from the non-iconic views. The data, models, and codes are downloadable from https://github.com/loadder/MR-Net.

Ye Pan, Kenny Mitchell
- Immersive technologies have increasingly attracted the attention of the computer animation community in search of more intuitive and effective alternatives to the current sophisticated 2D interfaces. The higher affordances offered by 3D interaction, as well as the enhanced spatial understanding have the potential to improve the animators’ task, which is tremendously skill intensive and time-consuming. We explore the capabilities provided by our PoseMMR, multiple users posing and animating characters in a mixed reality (MR) environment, animation via group-based expert walkthroughs. We demonstrated our system can facilitate immersive posing, animation editing, version control and collaboration. We provide a set of guidelines and discussed the benefits and potential of immersive technologies for our future animation toolsets.
Improving VIP viewer gaze estimation and engagement using adaptive dynamic anamorphosis
Ye Pan, Kenny Mitchell
- Anamorphosis for 2D displays can provide viewer centric perspective viewing, enabling 3D appearance, eye contact and engagement, by adapting dynamically in real time to a single moving viewer’s viewpoint, but at the cost of distorted viewing for other viewers. We present a method for constructing non-linear projections as a combination of anamorphic rendering of selective objects whilst reverting to normal perspective rendering of the rest of the scene. Our study defines a scene consisting of five characters, with one of these characters selectively rendered in anamorphic perspective. We conducted an evaluation experiment and demonstrate that the tracked viewer centric imagery for the selected character results in an improved gaze and engagement estimation. Critically, this is performed without sacrificing the other viewers’ viewing experience. In addition, we present findings on the perception of gaze direction for regularly viewed characters located off-center to the origin, where perceived gaze shifts from being aligned to misalignment increasingly as the distance between viewer and character increases. Finally, we discuss different viewpoints and the spatial relationship between objects.
Ye Pan, Anthony Steed
- The use of a self-avatar representation in head-mounted displays has been shown to have important effects on user behavior. However, relatively few studies focus on feet and legs. We implemented a shared virtual reality for consumer virtual reality systems where each user could be represented by a gender-matched self-avatar controlled by multiple trackers. The self-avatar allowed users to see their feet, legs and part of their torso when they looked down. We implemented an experiment where participants worked together to solve jigsaw puzzles. Participants experienced either no-avatar, a self-avatar with floating feet, or a self-avatar with tracked feet, in a between-subjects manipulation. First, we found that participants could solve the puzzle more quickly with self-avatars than without self-avatars; but there was no significant difference between the latter two conditions, solely on task completion time. Second, we found participants with tracked feet placed their feet statistically significantly closer to obstacles than participants with floating feet, whereas participants who did not have a self-avatar usually ignored obstacles. Our post-experience questionnaire results confirmed that the use of a self-avatar has important effects on presence and interaction. Together the results show that although the impact of animated legs might be subtle, it does change how users behave around obstacles. This could have important implications for the design of virtual spaces for applications such as training or behavioral analysis.
Avatar type affects performance of cognitive tasks in virtual reality
Ye Pan, Anthony Steed
- Current consumer virtual reality applications typically represent the user by an avatar comprising a simple head/torso and decoupled hands. In the prior work of Steed et al. it was shown that the presence or absence of an avatar could have a significant impact on the cognitive load of the user. We extend that work in two ways. First they only used a full-body avatar with articulated arms, so we add a condition with hands-only representation similar to the majority of current consumer applications. Second we provide a real-world benchmark so as to start to get at the impact of using any immersive system. We validate the prior results: real and full body avatar performance on a memory task is significantly better than no avatar. However the hands only condition is not significantly different than either these two extremes. We discuss why this might be, in particular we discuss the potential for a individual variation in response to the embodiment level.
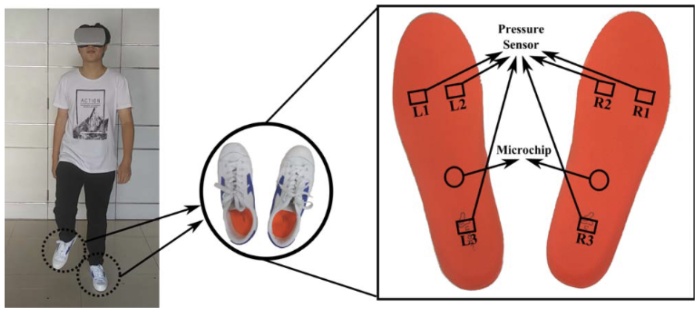
Accurate and fast classification of foot gestures for virtual locomotion
Xinyu Shi, Junjun Pan, Zeyong Hu, Juncong Lin, Shihui Guo, Minghong Liao, Ye Pan, Ligang Liu
- This work explores the use of foot gestures for locomotion in virtual environments. Foot gestures are represented as the distribution of plantar pressure and detected by three sparsely-located sensors on each insole. The Long Short-Term Memory model is chosen as the classifier to recognize the performer’s foot gesture based on the captured signals of pressure information. The trained classifier directly takes the noisy and sparse input of sensor data, and handles seven categories of foot gestures (stand, walk forward/backward, run, jump, slide left and right) without manual definition of signal features for classifying these gestures. This classifier is capable of recognizing the foot gestures, even with the existence of large sensor-specific, inter-person and intra-person variations. Results show that an accuracy of ~80% can be achieved across different users with different shoe sizes and ~85% for users with the same shoe size. A novel method, Dual-Check Till Consensus, is proposed to reduce the latency of gesture recognition from 2 seconds to 0.5 seconds and increase the accuracy to over 97%. This method offers a promising solution to achieve lower latency and higher accuracy at a minor cost of computation workload. The characteristics of high accuracy and fast classification of our method could lead to wider applications of using foot patterns for human-computer interaction.
Huixu Dong, Chen Qiu, Dilip K Prasad, Ye Pan, Jiansheng Dai, I-Ming Chen
- Performing a grasp is a pivotal capability for a robotic gripper. We propose a new evaluation approach of the quality of grasping stability via constructing a model of grasping stiffness based on the theory of contact mechanics. First, the mathematical models are built to explore “soft contact” and the general grasp stiffness between a finger and an object. Next, the grasping stiffness matrix is constructed to reflect the normal, tangential and torsion stiffness coefficients. Finally, we design two grasping cases to verify the proposed measurement criterion of the quality of grasping stability by comparing different grasping configurations. Specifically, a standard grasping index is used and compared with the minimum eigenvalue index of the constructed grasping stiffness we built. The comparison result reveals a similar tendency between them for measuring the quality of grasping stability and thus, validates the proposed approach.
Mubasir Kapadia, Carlos Manuel Muniz, Samuel S Sohn, Ye Pan, Sasha Schriber, Kenny Mitchell, Markus Gross
- JUNGLE is an interactive, visual platform for the collaborative manipulation and consumption of nonlinear transmedia stories. Intuitive visual interfaces encourage JUNGLE users to explore vast libraries of story worlds, expand existing stories, or conceive of entirely original story worlds. JUNGLE stories utilize multiple media forms including videos, images, and text, and accommodate branching narrative outcomes. We extensively evaluate Jungle using a focused small-scale study and free-form large-scale study with careful protection of study participant privacy. In the small-scale study, users found JUNGLE ’s features to be versatile, engaging, and intuitive for discovering new content. In the large-scale study, 354 subjects tested JUNGLE in a realistic 45-day scenario. We find that users collaborated on story worlds incorporating various forms of media in multiple (on average two) possible story paths. In particular, we find through initial observations that JUNGLE can evoke creativity: traditionally passive consumers gradually transition into active content creators. Supplementary videos showcasing the JUNGLE system and hypothetical example stories authored using JUNGLE independently hosted here and here.
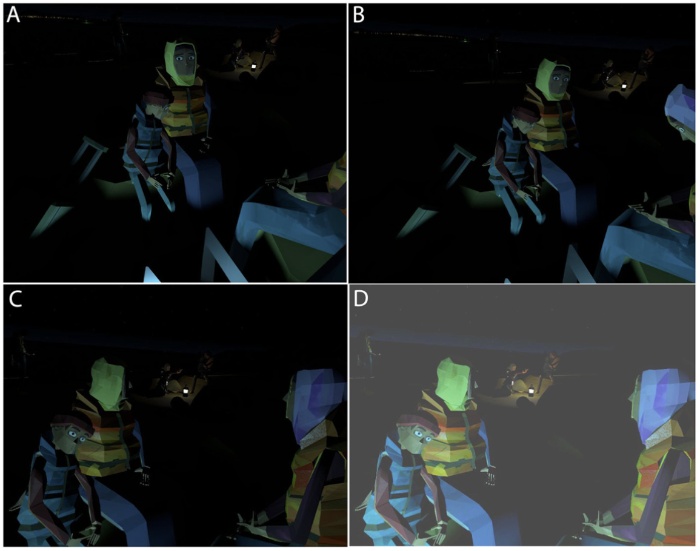
Anthony Steed, Ye Pan, Zillah Watson, Mel Slater
- A virtual reality scenario called “We Wait” gives people an immersive experience of the plight of refugees waiting to be picked up by a boat on a shore in Turkey to be illegally taken to Europe, crossing a dangerous stretch of sea. This was based on BBC news reporting of the refugee situation, but deliberately depicted as an animation with cartoon-like characters representing the refugees. Of interest was the level of presence that might be experienced by participants and the extent to which the scenario might prompt participants to follow-up further information about the refugee crisis. By presence we refer to both Place Illusion, the illusion of being in the rendered space, and Plausibility, the illusion that the unfolding events were really happening. The follow-up was assessed by whether and when participants accessed a web page that contained further information about the refugee crisis after the experiment. Two factors were considered in a balanced between-groups design with 32 participants. The Responsiveness factor was either “None” or “Look at.” In the first the virtual characters in the scenario never responded to actions of the participant, and in the second they would occasionally look at the participant after the participant looked at them. The second factor was Embodiment, which was either “No Body” or “Body.” In the No Body condition participants had no virtual body, and in the Body condition they would see a virtual body spatially congruent with their own if they looked down toward themselves. The virtual body was animated by the head tracking move the upper body. The results showed that the major factor positively contributing to presence was Responsiveness (“Look at”), and that Embodiment (“Body”) may have contributed but to a lesser extent. There were important differences between men and woman in the degree of follow-up, with men more likely to do so than women. The experiment shows that adding in some simple responses in an immersive journalism scenario, where the characters acknowledge the presence of the participant through gaze, can enhance the degree of presence felt by the participants.

Empowerment and embodiment for collaborative mixed reality systems
Ye Pan, David Sinclair, Kenny Mitchell
- We present several mixed‐reality‐based remote collaboration settings by using consumer head‐mounted displays. We investigated how two people are able to work together in these settings. We found that the person in the AR system will be regarded as the “leader” (i.e., they provide a greater contribution to the collaboration), whereas no similar “leader” emerges in augmented reality (AR)‐to‐AR and AR‐to‐VRBody settings. We also found that these special patterns of leadership only emerged for 3D interactions and not for 2D interactions. Results about the participants’ experience of leadership, collaboration, embodiment, presence, and copresence shed further light on these findings.
The impact of self-avatars on trust and collaboration in shared virtual environments
Ye Pan, Anthony Steed
- A self-avatar is known to have a potentially significant impact on the user’s experience of the immersive content but it can also affect how users interact with each other in a shared virtual environment (SVE). We implemented an SVE for a consumer virtual reality system where each user’s body could be represented by a jointed self-avatar that was dynamically controlled by head and hand controllers. We investigated the impact of a self-avatar on collaborative outcomes such as completion time and trust formation during competitive and cooperative tasks. We used two different embodiment levels: no self-avatar and self-avatar, and compared these to an in-person face to face version of the tasks. We found that participants could finish the task more quickly when they cooperated than when they competed, for both the self-avatar condition and the face to face condition, but not for the no self-avatar condition. In terms of trust formation, both the self-avatar condition and the face to face condition led to higher scores than the no self-avatar condition; however, collaboration style had no significant effect on trust built between partners. The results are further evidence of the importance of a self-avatar representation in immersive virtual reality.
The impact of a self-avatar on cognitive load in immersive virtual reality
Anthony Steed, Ye Pan, Fiona Zisch, William Steptoe
- The use of a self-avatar inside an immersive virtual reality system has been shown to have important effects on presence, interaction and perception of space. Based on studies from linguistics and cognition, in this paper we demonstrate that a self-avatar may aid the participant’s cognitive processes while immersed in a virtual reality system. In our study participants were asked to memorise pairs of letters, perform a spatial rotation exercise and then recall the pairs of letters. In a between-subject factor they either had an avatar or not, and in a within-subject factor they were instructed to keep their hands still or not. We found that participants who both had an avatar and were allowed to move their hands had significantly higher letter pair recall. There was no significant difference between the other three conditions. Further analysis showed that participants who were allowed to move their hands, but could not see the self-avatar, usually didn’t move their hands or stopped moving their hands after a short while. We argue that an active self-avatar may alleviate the mental load of doing the spatial rotation exercise and thus improve letter recall. The results are further evidence of the importance of an appropriate self-avatar representation in immersive virtual reality.

An ‘in the wild’experiment on presence and embodiment using consumer virtual reality equipment
Anthony Steed, Sebastian Frlston, Maria Murcia Lopez, Jason Drummond, Ye Pan, David Swapp
- Consumer virtual reality systems are now becoming widely available. We report on a study on presence and embodiment within virtual reality that was conducted `in the wild’, in that data was collected from devices owned by consumers in uncontrolled settings, not in a traditional laboratory setting. Users of Samsung Gear VR and Google Cardboard devices were invited by web pages and email invitation to download and run an app that presented a scenario where the participant would sit in a bar watching a singer. Each participant saw one of eight variations of the scenario: with or without a self-avatar; singer inviting the participant to tap along or not; singer looking at the participant or not. Despite the uncontrolled situation of the experiment, results from an in-app questionnaire showed tentative evidence that a self-avatar had a positive effect on self-report of presence and embodiment, and that the singer inviting the participant to tap along had a negative effect on self-report of embodiment. We discuss the limitations of the study and the platforms, and the potential for future open virtual reality experiments.
A comparison of avatar-, Video-, and robot-Mediated interaction on Users’ Trust in expertise
Ye Pan, Anthony Steed
- Communication technologies are becoming increasingly diverse in form and functionality. A central concern is the ability to detect whether others are trustworthy. Judgments of trustworthiness rely, in part, on assessments of non-verbal cues, which are affected by media representations. In this research, we compared trust formation on three media representations. We presented 24 participants with advisors represented by two of the three alternate formats: video, avatar, or robot. Unknown to the participants, one was an expert, and the other was a non-expert. We observed participants’ advice-seeking behavior under risk as an indicator of their trust in the advisor. We found that most participants preferred seeking advice from the expert, but we also found a tendency for seeking robot or video advice. Avatar advice, in contrast, was more rarely sought. Users’ self-reports support these findings. These results suggest that when users make trust assessments, the physical presence of the robot representation might compensate for the lack of identity cues.
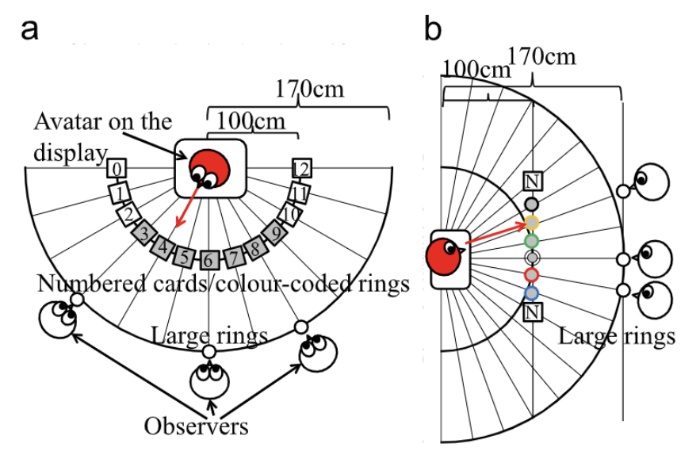
Effects of 3D perspective on head gaze estimation with a multiview autostereoscopic display
Ye Pan, Anthony Steed
- Head gaze, or the orientation of the head, is a very important attentional cue in face to face conversation. Some subtleties of the gaze can be lost in common teleconferencing systems, because a single perspective warps spatial characteristics. A recent random hole display is a potentially interesting display for group conversation, as it allows multiple stereo viewers in arbitrary locations, without the restriction of conventional autostereoscopic displays on viewing positions. We represented a remote person as an avatar on a random hole display. We evaluated this system by measuring the ability of multiple observers with different horizontal and vertical viewing angles to accurately and simultaneously judge which targets the avatar is gazing at. We compared three perspective conditions: a conventional 2D view, a monoscopic perspective-correct view, and a stereoscopic perspective-correct views. In the latter two conditions, the random hole display shows three and six views simultaneously. Although the random hole display does not provide high quality view, because it has to distribute display pixels among multiple viewers, the different views are easily distinguished. Results suggest the combined presence of perspective-correct and stereoscopic cues significantly improved the effectiveness with which observers were able to assess the avatar’s head gaze direction. This motivates the need for stereo in future multiview displays.
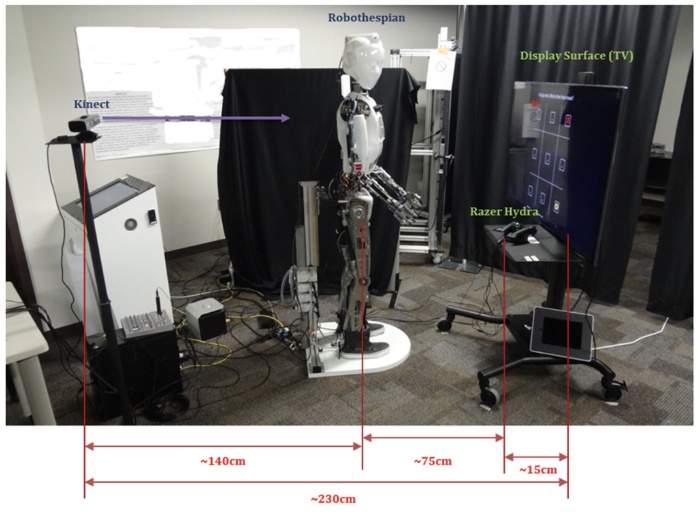
Symmetric telepresence using robotic humanoid surrogates
Arjun Nagendran, Anthony Steed, Brian Kelly, Ye Pan
- Telepresence involves the use of virtual reality technology to facilitate apparent physical participation in distant events, including potentially performing tasks, while creating a sense of being in that location. Traditionally, such systems are asymmetric in nature where only one side (participant) is “teleported” to the remote location. In this manuscript, the authors explore the possibility of symmetric three-dimensional telepresence where both sides (participants) are “teleported” simultaneously to each other’s location; the overarching concept of symmetric telepresence in virtual environments is extended to telepresence robots in physical environments. Two identical physical humanoid robots located in UK and the USA serve as surrogates while performing a transcontinental shared collaborative task. The actions of these surrogate robots are driven by capturing the intent of the participants controlling them in either location. Participants could communicate verbally but could not see the other person or the remote location while performing the task. The effectiveness of gesturing along with other observations during this preliminary experiment is presented. Results reveal that the symmetric robotic telepresence allowed participants to use and understand gestures in cases where they would otherwise have to describe their actions verbally.
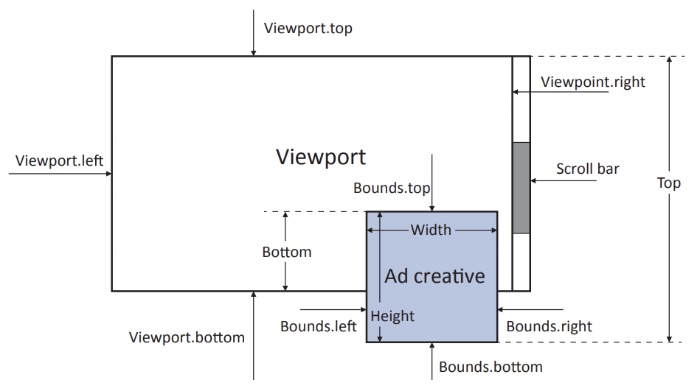
An empirical study on display ad impression viewability measurements
Weinan Zhang, Ye Pan, Tianxiong Zhou, Jun Wang
- Display advertising normally charges advertisers for every single ad impression. Specifically, if an ad in a webpage has been loaded in the browser, an ad impression is counted. However, due to the position and size of the ad slot, lots of ads are actually not viewed but still measured as impressions and charged. These fraud ad impressions indeed undermine the efficacy of display advertising. A perfect ad impression viewability measurement should match what the user has really viewed with a short memory. In this paper, we conduct extensive investigations on display ad impression viewability measurements on dimensions of ad creative displayed pixel percentage and exposure time to find which measurement provides the most accurate ad impression counting. The empirical results show that the most accurate measurement counts one ad impression if more than 75% of the ad creative pixels have been exposed for at least 2 continuous seconds.
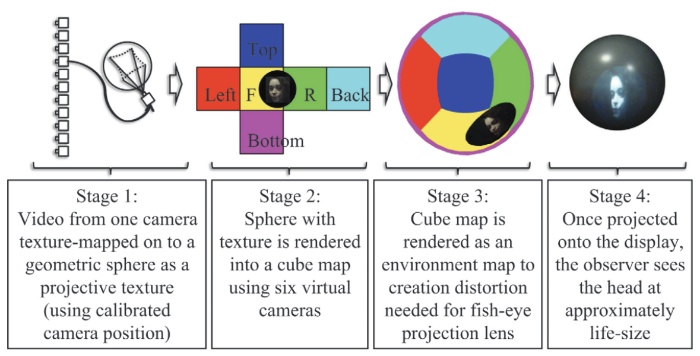
Ye Pan, Oyewole Oyekoya, Anthony Steed
- We propose a new video conferencing system that uses an array of cameras to capture a remote user and then show the video of that person on a spherical display. This telepresence system has two key advantages: (i) it can capture a near-correct image for any potential observer viewing direction because the cameras surround the user horizontally; and (ii) with view-dependent graphical representation on the spherical display, it is possible to tell where the remote user is looking from any viewpoint, whereas flat displays are visible only from the front. As a result, the display can more faithfully represent the gaze of the remote user. We evaluate this system by measuring the ability of observers to accurately judge which targets the actor is gazing at in two experiments. Results from the first experiment demonstrate the effectiveness of the camera array and spherical display system, in that it allows observers at multiple observing positions to accurately tell at which targets the remote user is looking. The second experiment further compared a spherical display with a planar display and provided detailed reasons for the improvement of our system in conveying gaze. We found two linear models for predicting the distortion introduced by misalignment of capturing cameras and the observer’s viewing angles in video conferencing systems. Those models might be able to enable a correction for this distortion in future display configurations.

A gaze-preserving situated multiview telepresence system
Ye Pan, Anthony Steed
- Gaze, attention, and eye contact are important aspects of face to face communication, but some subtleties can be lost in videoconferencing because participants look at a single planar image of the remote user. We propose a low-cost cylindrical videoconferencing system that preserves gaze direction by providing perspective-correct images for multiple viewpoints around a conference table. We accomplish this by using an array of cameras to capture a remote person, and an array of projectors to present the camera images onto a cylindrical screen. The cylindrical screen reflects each image to a narrow viewing zone. The use of such a situated display allows participants to see the remote person from multiple viewing directions. We compare our system to three alternative display configurations. We demonstrate the effectiveness of our system by showing it allows multiple participants to simultaneously tell where the remote person is placing their gaze.
Comparing flat and spherical displays in a trust scenario in avatar-mediated interaction
Ye Pan, William Steptoe, Anthony Steed
- We report on two experiments that investigate the influence of display type and viewing angle on how people place their trust during avatar-mediated interaction. By monitoring advice seeking behavior, our first experiment demonstrates that if participants observe an avatar at an oblique viewing angle on a flat display, they are less able to discriminate between expert and non-expert advice than if they observe the avatar face-on. We then introduce a novel spherical display and a ray-traced rendering technique that can display an avatar that can be seen correctly from any viewing direction. We expect that a spherical display has advantages over a flat display because it better supports non-verbal cues, particularly gaze direction, since it presents a clear and undistorted viewing aspect at all angles. Our second experiment compares the spherical display to a flat display. Whilst participants can discriminate expert advice regardless of display, a negative bias towards the flat screen emerges at oblique viewing angles. This result emphasizes the ability of the spherical display to be viewed qualitatively similarly from all angles. Together the experiments demonstrate how trust can be altered depending on how one views the avatar.
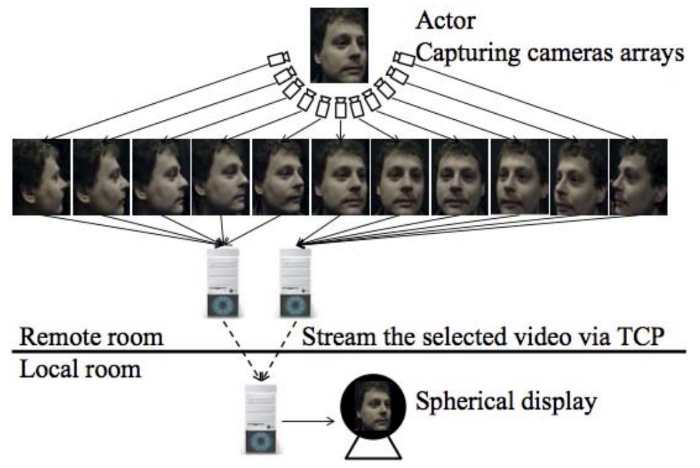
Preserving gaze direction in teleconferencing using a camera array and a spherical display
Ye Pan, Anthony Steed
- The movement of human gaze is very important in face to face conversation. Some of the quality of that movement is lost in videoconferencing because the participants look at a single planar image of the remote person. We use an array of cameras to capture a remote user, and then display video of that person on a spherical display. We compare the spherical display to a face to face setting and a planar display. We demonstrate the effectiveness of the camera array and spherical display system in that it allows observers to accurately judge where the remote user is placing their gaze.